Building QuickSight Datasets with CDK - S3
AWS BI solution Amazon QuickSight provides a neat and powerful web console to handle most use cases. Nevertheless, as soon as a need for automation appears, relying on IaC can help increase productivity.
Today we’ll take a look at how to build QuickSight datasets using CDK. We’ll focus on building a QuickSight dataset for data readily available in S3. The Quicksight dataset will contain data from the famous titanic dataset.
In order to understand IaC code it’s usually a good idea to first have a mental model of what we’re trying to build. Our goal is to get a dataset in Quicksight. This dataset will be based on a CSV-file which we upload to S3. Permission management is in many cases the starting point when implementing architectures. That’s why we’ll also do this - Quicksight needs to be able to talk to S3 to load our data for example. Afterwards we need to specify some meta-information for Quicksight to be able to read the data - a manifest file that points to the data in S3. Having created that, we can create the data source with the pointer to said manifest. Next we can create a table from the data source to have something to base our analysis on. We first create a physical table that represents the CSV file. Unfortunately there are some limitations for the data types of CSV-based tables, so we create a logical table on top of the physical table to set the correct data types. Logical table allow you to transform the data in the underlying physical table to suit your use case. Let’s get started.
QuickSight ?
Amazon QuickSight is a scalable serverless and embeddable business intelligence service built for the cloud that features machine learning.
QuickSight Datasets
A QuickSight dataset identifies the specific data in a data source that we want to use. QuickSight support a large number of data sources. In this post we will focus on Amazon S3. An exhaustive list of supported data sources is available in quicksight supported data sources documentation.
QuickSight datasets can either be directly queried from their respective data source or be stored in Amazon QuickSight SPICE (Super-fast, Parallel, In-memory Calculation Engine) for faster processing. In direct query mode QuickSight will generate a timeout after 2 minutes. However some database drivers such as Redshift may not react to it.
Permissions
QuickSight allows you to set resources level permissions in the same way resource permissions are set through IAM. When building resources, QuickSight will look for the service-role aws-quicksight-s3-consumers-role-v0 and fall back to aws-quicksight-service-role-v0 if the first one is not found so you have to make sure that at least the service role aws-quicksight-service-role-v0 is available and grant proper permissions to these roles.
qs_service_role_names = [
"aws-quicksight-service-role-v0",
"aws-quicksight-s3-consumers-role-v0",
]
qs_managed_policy = iam.CfnManagedPolicy(
self,
"QuickSightPolicy",
managed_policy_name="QuickSightDemoS3Policy",
policy_document=dict(
Statement=[
dict(
Action=["s3:ListAllMyBuckets"],
Effect="Allow",
Resource=["arn:aws:s3:::*"],
),
dict(
Action=["s3:ListBucket"],
Effect="Allow",
Resource=[
f"arn:aws:s3:::{bucket_name}",
],
),
dict(
Action=[
"s3:GetObject",
"s3:List*",
],
Effect="Allow",
Resource=[
f"arn:aws:s3:::{bucket_name}/files/*",
],
),
],
Version="2012-10-17",
),
roles=qs_service_role_names,
)
In case the deployment fail due to the service role aws-quicksight-s3-consumers-role-v0 not been found, just remove it from the list qs_service_role_names.
As principal you can use QuickSight users (e.g. arn:aws:quicksight:${Region}:12345678910:user/default/username) or QuickSight groups (e.g. arn:aws:quicksight:${Region}:12345678910:group/default/groupname)
Following data source permissions can be used:
-
Readonly:
[ "quicksight:DescribeDataSource", "quicksight:DescribeDataSourcePermissions", "quicksight:PassDataSource" ] -
Read/Write:
[ "quicksight:DescribeDataSource","quicksight:DescribeDataSourcePermissions", "quicksight:PassDataSource","quicksight:UpdateDataSource", "quicksight:DeleteDataSource","quicksight:UpdateDataSourcePermissions" ]
Read only access to the data source is enough so we define our permissions as follow:
qs_data_source_permissions = [
quicksight.CfnDataSource.ResourcePermissionProperty(
principal=qs_principal_arn,
actions=[
"quicksight:DescribeDataSource",
"quicksight:DescribeDataSourcePermissions",
"quicksight:PassDataSource",
],
),
]
Following dataset permissions can be used:
-
Readonly:
[ "quicksight:DescribeDataSet","quicksight:DescribeDataSetPermissions", "quicksight:PassDataSet","quicksight:DescribeIngestion","quicksight:ListIngestions" ] -
Read/Write:
[ "quicksight:DescribeDataSet","quicksight:DescribeDataSetPermissions","quicksight:PassDataSet", "quicksight:DescribeIngestion","quicksight:ListIngestions","quicksight:UpdateDataSet", "quicksight:DeleteDataSet","quicksight:CreateIngestion","quicksight:CancelIngestion", "quicksight:UpdateDataSetPermissions" ]
Just as with the data source, we will provide read only access to the data set.
qs_dataset_permissions = [
quicksight.CfnDataSet.ResourcePermissionProperty(
principal=qs_principal_arn,
actions=[
"quicksight:DescribeDataSet",
"quicksight:DescribeDataSetPermissions",
"quicksight:PassDataSet",
"quicksight:DescribeIngestion",
"quicksight:ListIngestions",
],
)
]
Data sources
To use Amazon S3 as data source a manifest is required with information about the files to select for the datasets and meta information such as the availability of header or delimiters. At least one of fileLocations.URIs or fileLocations.URIPrefixes should be provided.
A manifest file for the titanic dataset looks as follow:
{
"fileLocations": [
{
"URIs": [
"s3://my-bucket-name/files/path-to/my-file.csv",
]
},
{
"URIPrefixes": [
"s3://my-second-bucket-name/files/my-csv-folder",
]
}
],
"globalUploadSettings": {
"format": "CSV",
"delimiter": ",",
"containsHeader": "true"
}
}
The attribute globalUploadSettings.textqualifier was not set as no text qualifier is required in the titanic file. QuickSight service roles should have read access to the manifest file as well as files and folders listed in the manifest.
Quicksight expects manifest files to specify up to 1000 files.
Now that we have a manifest and permissions, let’s upload the manifest to $bucket_name/$manifest_key. Considering the Policy we previously created, the manifest should be located at $bucket_name/files/... to be readable by the QuickSight service role.
We are ready to create our S3 data source.
qs_s3_data_source_name = "s3-titanic"
qs_s3_data_source = quicksight.CfnDataSource(
scope=self,
id="S3Datasource",
name=qs_s3_data_source_name,
data_source_parameters=quicksight.CfnDataSource.DataSourceParametersProperty(
s3_parameters=quicksight.CfnDataSource.S3ParametersProperty(
manifest_file_location=quicksight.CfnDataSource.ManifestFileLocationProperty(
bucket=bucket_name,
key=manifest_key,
)
)
),
type="S3",
aws_account_id=self.account,
data_source_id=qs_s3_data_source_name,
ssl_properties=quicksight.CfnDataSource.SslPropertiesProperty(
disable_ssl=False
),
permissions=qs_data_source_permissions,
)
Datasets
Once our data source is created we are ready to create our data set. Data sets are constituted of physical and logical tables. Physical tables describe the data at the input level and logical tables describe how the data should be transformed to be presented as output.
Let’s first create the physical table for the titanic dataset. Datasets physical tables build using non JSON files from S3 can only have STRING as input column type. So we have the following declaration:
qs_s3_dataset_titanic_physical_table = (
quicksight.CfnDataSet.PhysicalTableProperty(
s3_source=quicksight.CfnDataSet.S3SourceProperty(
data_source_arn=qs_s3_data_source.attr_arn,
upload_settings=quicksight.CfnDataSet.UploadSettingsProperty(
contains_header=True,
delimiter=",",
format="CSV",
),
input_columns=[
quicksight.CfnDataSet.InputColumnProperty(
name="Survived", type="STRING"
),
quicksight.CfnDataSet.InputColumnProperty(
name="Pclass", type="STRING"
),
quicksight.CfnDataSet.InputColumnProperty(
name="Name", type="STRING"
),
quicksight.CfnDataSet.InputColumnProperty(
name="Sex", type="STRING"
),
quicksight.CfnDataSet.InputColumnProperty(
name="Age", type="STRING"
),
quicksight.CfnDataSet.InputColumnProperty(
name="Siblings/Spouses Aboard", type="STRING"
),
quicksight.CfnDataSet.InputColumnProperty(
name="Parents/Children Aboard", type="STRING"
),
quicksight.CfnDataSet.InputColumnProperty(
name="Fare", type="STRING"
),
],
)
)
)
It is however possible to cast columns to another data type using a logical table. As we know the real data types of the titanic file, we simply cast the loaded String in the physical table to the real data types. Supported data types are: BIT, BOOLEAN, DATETIME, DECIMAL, INTEGER, STRING and JSON.
qs_s3_dataset_titanic_logical_table = quicksight.CfnDataSet.LogicalTableProperty(
alias="s3-titanic-cast",
source=quicksight.CfnDataSet.LogicalTableSourceProperty(
physical_table_id="s3-titanic"
),
data_transforms=[
quicksight.CfnDataSet.TransformOperationProperty(
cast_column_type_operation=quicksight.CfnDataSet.CastColumnTypeOperationProperty(
column_name="Survived", new_column_type="INTEGER"
)
),
quicksight.CfnDataSet.TransformOperationProperty(
cast_column_type_operation=quicksight.CfnDataSet.CastColumnTypeOperationProperty(
column_name="Pclass", new_column_type="INTEGER"
)
),
quicksight.CfnDataSet.TransformOperationProperty(
cast_column_type_operation=quicksight.CfnDataSet.CastColumnTypeOperationProperty(
column_name="Age", new_column_type="INTEGER"
)
),
quicksight.CfnDataSet.TransformOperationProperty(
cast_column_type_operation=quicksight.CfnDataSet.CastColumnTypeOperationProperty(
column_name="Siblings/Spouses Aboard",
new_column_type="INTEGER",
)
),
quicksight.CfnDataSet.TransformOperationProperty(
cast_column_type_operation=quicksight.CfnDataSet.CastColumnTypeOperationProperty(
column_name="Parents/Children Aboard",
new_column_type="INTEGER",
)
),
quicksight.CfnDataSet.TransformOperationProperty(
cast_column_type_operation=quicksight.CfnDataSet.CastColumnTypeOperationProperty(
column_name="Fare", new_column_type="DECIMAL"
)
),
],
)
Make sure to upload the file titanic.csv (data/titanic.csv in the companion) to one of the locations specified in your manifest.
We can now build the QuickSight dataset:
qs_import_mode = "SPICE"
qs_s3_dataset_titanic_name = "s3-titanic-ds"
qs_s3_dataset_titanic = quicksight.CfnDataSet(
scope=self,
id="S3Titanic",
aws_account_id=self.account,
physical_table_map={"s3-titanic": qs_s3_dataset_titanic_physical_table},
logical_table_map={"s3-titanic": qs_s3_dataset_titanic_logical_table},
name=qs_s3_dataset_titanic_name,
data_set_id=qs_s3_dataset_titanic_name,
permissions=qs_dataset_permissions,
import_mode=qs_import_mode,
)
Code
The full code is available in the companion on Github.
If everything went smoothly you should now be able to see the dataset in QuickSight.
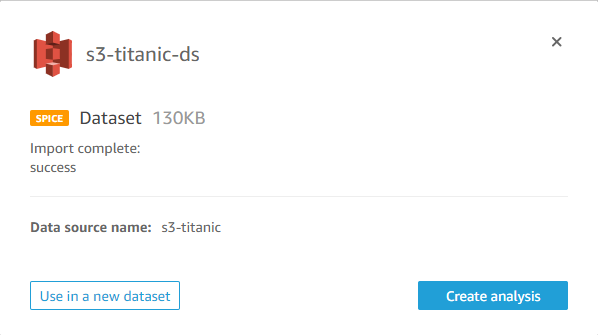
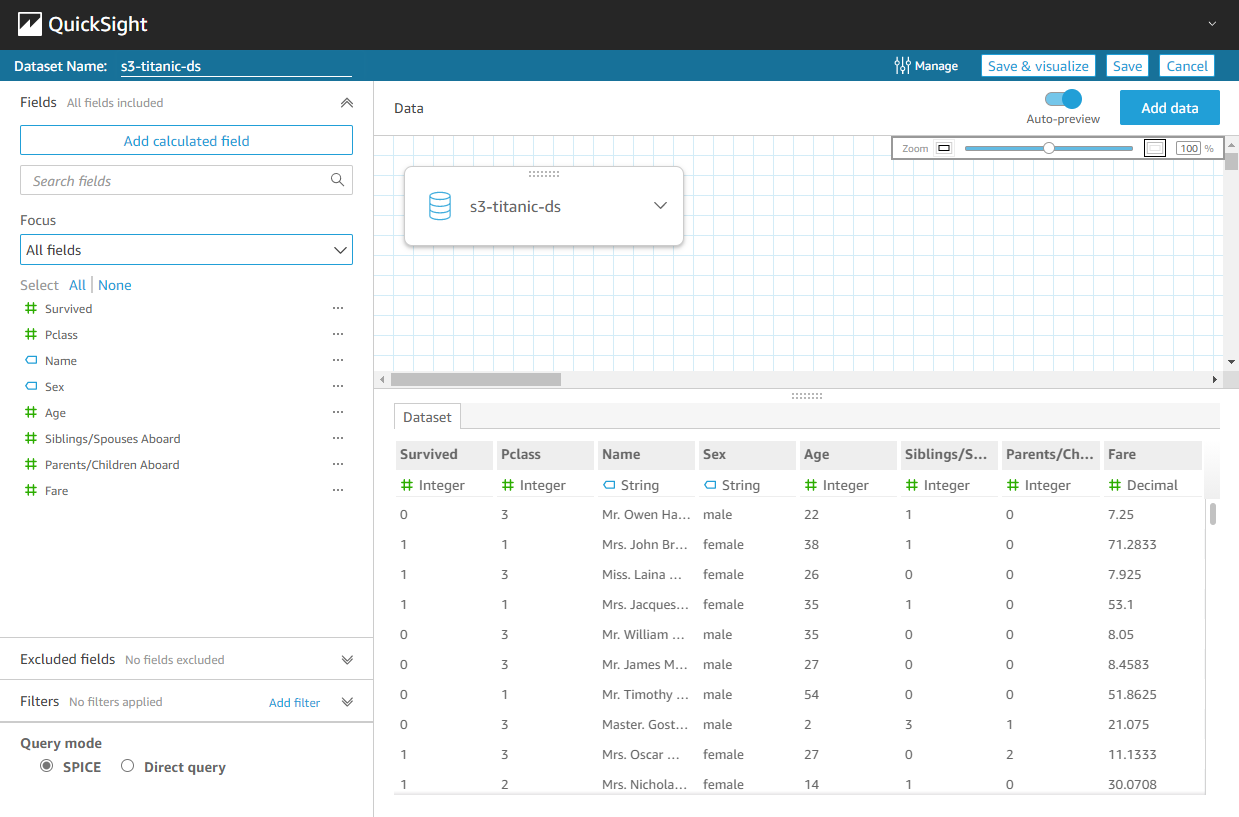
Clicking on the dataset and selecting the option Use in a new dataset should allow you to preview it without directly creating an analysis.
Summary
In this post we had a brief introduction to Quicksight and took a look at how to build a QuickSight dataset with CDK using S3 as data source.
This may seem like a lot of work for a single Dataset when compared to the effort required to create the same dataset using the QuickSight web console. However it makes sense to use CDK or any other IaC solution for such a task if you have to build such a dataset in multiple accounts. Hope you found this blog post helpful.