Multi-AZ Block Storage for EKS - Architecture
On the heels of the recent announcement of our consulting offer for multi-AZ block storage for EKS, it is worth discussing some of the base technologies. Let’s look into the idea and how it works under the hood.
The whole solution took half a year to explore, develop, and validate - with the help of AWS Solution Architects and NetApp Solution Architects as well. Thanks to everyone involved, and we are looking forward to cooperate on extending this offer in the future.
FSx for NetApp ONTAP
Since 2021 Amazon has offered “FSx for NetApp ONTAP” (short: FSxN), a managed service based on NetApp’s flagship storage product. ONTAP systems have been powering a lot of on-premises infrastructure for over a decade. They natively offer ways of synchronously replicating data across multiple geographies, automated failover/failback, and many additional concepts.
While many companies “born in the cloud” might see those storage systems as outdated, expensive, and maintenance-intense, they are often unaware of the technological advantages. Instant clones of test data in the Terabyte range, storage efficiency methods to cram 10x the data on a hard drive as with conventional usage, synchronous data replication, and WORM capabilities, … the list goes on.
Many of these features are now available on AWS and can enhance development/test efforts, AI and data science use-cases, as well as easy migration and operations of enterprise applications.
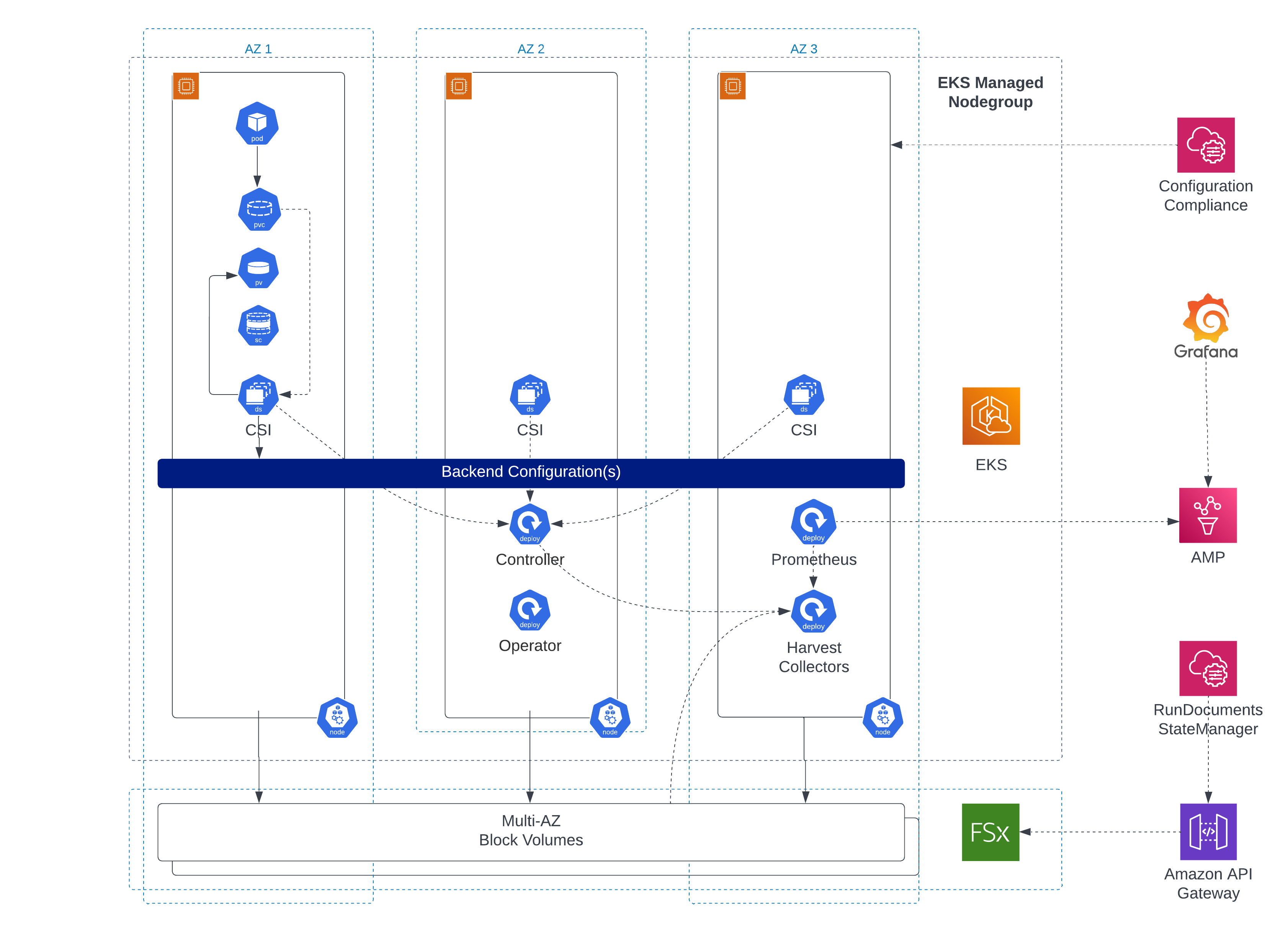
Architecture
If you choose the multi-AZ deployment model, replication with FSxN works across two AZs. In this mode, an active and one passive node automatically replicate data on their backend storage (aggregate in NetApp’s terms). While this is called a “Filesystem” in the FSx microcosm, it is a cluster in NetApp terminology.
NetApp supports native multi-tenancy, where an intermediate concept called a Storage virtual machine (SVM) comes into place. These are NetApp-native virtual machines that then offer storage to clients. Think of them as being responsible for different departments, EKS clusters, etc. All of these can be managed independently by dedicated users and provide storage to clients.
SVMs offer file shares (NAS, CIFS) just like EFS and other FSx services do - or they offer block storage via the ISCSI protocol. While file shares are visible in the AWS Web console, ISCSI is currently only configurable via ONTAP CLI/API.
Replication
Whether you choose a file share or map block storage via ISCSI - the underlying replication stays the same. You only write to the active node of the cluster, which will write it locally. Then, it will transfer it to the passive node, and after there is acknowledgment about writing the data, it will signal success back.
This process sounds very time-consuming but is a quick operation due to the underlying architecture. I will show some benchmarks at the end of this post.
Access Methods
Access differs significantly between file shares and block storage on FSxN:
With NAS protocols (NFS, CIFS), you use the concept of a Floating IP: This is a standalone IP which is not part of your VPC. Instead, it will be mapped to one of the network interfaces (ENI) of the FSxN cluster. By default, the corresponding route table entry will point at the primary node’s ENI. In case of a failover event, the secondary node takes over, and the route table will be modified to use its ENI instead.
This makes for some odd routing when you try to access this storage outside the VPC. By default, it will belong to the rather exotic IP range 198.19.0.0/16. What seems like a public IP range is part of another, lesser-known private range specified in RFC2544 for benchmarking purposes. As it is private and non-routed, this makes up for an excellent range to use and avoid address collisions with the already crowded RFC1918 spaces of 10.0.0.0/8, 172.16.0.0/12 and 192.168.0.0/16 or the RFC6598 space of 100.64.0.0/10.
Consequently, this IP can cause problems, especially if you want to reference it from load balancers, etc., as it is technically not part of the VPC address space.
On the other hand, SAN protocols (in this case, ISCSI) only use IPs from the VPC. They allocate one IP for the active node and one for the passive per SVM. Operating systems know how to work with multiple IPs for ISCSI devices and utilize multipathing to determine where to direct IO requests.
This principle makes ISCSI easy to route and uses long-tested OS-level drivers for accessing and failover. In reality, failover will be automatic and not impact the application significantly - the OS will switch active addresses quickly and transparently.
If you inspect ISCSI devices used on an instance, you will see that they appear with names as /dev/sda and do not indicate they are network-based. This information only appears if you pull back the curtain using commands like multipath -ll, sanlun lun show all, or their Windows equivalents.
# sanlun lun show -p
ONTAP Path: eks-storage-svm:/vol/trident_lun_pool_trident_DTZIQSCCRL/trident_pvc_701a8a72_1ffd_4db3_b060_4aa473220449
LUN: 2
LUN Size: 100g
Product: cDOT
Host Device: 3600a09806c574230475d537a77624479
Multipath Policy: service-time 0
Multipath Provider: Native
--------- ---------- ------- ------------ ----------------------------------------------
host server
path path /dev/ host vserver
state type node adapter LIF
--------- ---------- ------- ------------ ----------------------------------------------
up primary sda host0 iscsi_1
up secondary sdb host1 iscsi_2
NetApp offers their Host Utilities (available on the NetApp download portal) to optimize settings for each OS, which will set all OS parameters to maximize performance and failover behavior.
EKS Integration: NetApp Trident
Kubernetes 1.13 introduced an interface to integrate different storage systems, called Container Storage Interface(CSIs). This extends the native Kubernetes storage options to virtually any other storage.
EKS already offers the EBS CSI to use EBS block storage on Pods.
Likewise, NetApp developed a CSI for all their storage products: Trident. It supports physical storage like AFF/FAS-Systems, E-Series1, SolidFire/HCI, and cloud-based solutions like Azure NetApp Files, Cloud Volumes Service for Google Cloud - and Amazon FSx for NetApp ONTAP.
All these backends can be mapped into Kubernetes-native storage classes and will be available just as they were local storage. The advantage of CSI drivers is clear: they offer a transparent swap of storage backends without any modification to the deployed workloads.
Some CSI drivers also offer additional features like efficient snapshotting and cloning of volumes. With Trident, it is possible to use ONTAP’s near-instant cloning capabilities to duplicate huge volumes of testing- or training data.
Backends get addressed with specific backend drivers within Trident. If you want to manage ONTAP-based storage like FSxN, you have a few alternatives:
ontap-nas: NFS based file share, one Persistent Volume Claim (PVC) per FSx volumeontap-nas-economy: NFS, aggregates 100s of PVCs into one FSx volumeontap-nas-flexgroup: NFS, aggregate into volumes of up to 20PB size (192GB on FSxN)ontap-san: ISCSI based devices, one PVS per FSx volumeontap-san-economy: ISCSI, aggregates 100s of PVCs into one FSx volume
It is not advisable to use the ontap-nas or ontap-san backends, as the current quota of volumes per FSx is 500. With bigger Kubernetes clusters, this might not be enough. In contrast, the ontap-nas-economy, ontap-nas-flexgroup, and ontap-san-economy backends can easily manage 100 and more ISCSI storage containers (LUNs) per volume.
Architecture
Trident usually gets deployed via Helm chart, as Custom Resource Definitions (CRDs) or via OperatorHub.io. It consists of:
- a dedicated namespace (
trident) - an operator which manages the deployment of the CSI driver on all nodes of the EKS cluster
- an orchestrator which manages storage requests, backend mappings, and maintenance tasks
- a DaemonSet of the CSI driver to provide storage on all nodes
- CRDs to define the characteristics of the storage backends
- one or more backend definitions (connections to storage systems, FSxN, etc.)
While there is a fourth alternative of deploying Trident (tridentctl), it is not recommended anymore, as it does not automatically adjust in the case of new nodes joining the Kubernetes cluster.
This architecture also means that as soon as a Kubernetes workload requests a Physical Volume, Trident will automatically manage its whole lifecycle (including deletion after de-provisioning).
Use FSxN with EKS
While this is an AWS-centric post, we needed this info from the NetApp universe on backends, storage protocols, and Trident to connect the storage solution with our EKS clusters. So let’s go ahead and show the missing pieces to glue everything together.
Backend definition
After creating an FSxN filesystem, you need to create a new SVM for hosting your block storage devices. The resulting page will also include the Floating IP, essential to access your cluster’s management API. Now you can create a new Backend with the SVM login data, IP, and the ontap-san-economy backend.
---
apiVersion: v1
kind: Secret
metadata:
name: fsxn-san-backend-secret
namespace: trident
type: Opaque
stringData:
username: vsadmin
password: SuperSecret
---
apiVersion: trident.netapp.io/v1
kind: TridentBackendConfig
metadata:
name: fsxn-san-backend-tbc
namespace: trident
spec:
version: 1
storageDriverName: ontap-san-economy
backendName: fsxn-san-backend
managementLIF: 198.19.255.123 # This will vary
svm: eks-storage-svm
credentials:
name: fsxn-san-backend-secret
Now, we have to map the proprietary Trident backend definition with Kubernetes’ storage classes:
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fsxn-san-eco
provisioner: csi.trident.netapp.io
parameters:
backendType: ontap-san-economy
provisioningType: thin
This definition enables us to use the storage just as if we accessed any other Kubernetes storage. Create a PVC with the desired access mode and capacity, and you can use this with your workloads.
For production workloads, there are a lot of additional settings. Proper security groups, authentication with CHAP instead of passwords, Infrastructure as Code, the configuration of snapshot providers/storage reclamation/ISCSI parameters, etc.
Still, this should suffice to get the first taste of Multi-AZ block storage with your EKS cluster. If you want to know more about what we offer around this, read the original announcement blog and give us a call or email.
Benchmarks
So, how fast is FSxN in reality? This is a valid question after the earlier explanations on how synchronous replication works and the various abstraction layers involved.
The answer will depend heavily on your workload, environment, and access patterns. Synthetic benchmarks using tools like fio and ioping can only be an indication - but reality will vary.
I benchmarked a standard FSxN volume with a minimum of 1,024 GB of capacity, 3,072 IOPS, and 512 MB/s of throughput across two AZs.
> fio --randrepeat=1 --ioengine=libaio --direct=1 --gtod_reduce=1 --name=fiotest --filename=testfio --bs=4k --iodepth=64 --size=32G --readwrite=randrw --rwmixread=75
fio-2.14
...
read : io=24575MB, bw=126732KB/s, iops=31682, runt=198569msec
write: io=8192.9MB, bw=42249KB/s, iops=10562, runt=198569msec
cpu : usr=5.32%, sys=25.61%, ctx=2880411, majf=0, minf=10
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.1%, >=64=0.0%
issued : total=r=6291254/w=2097354/d=0, short=r=0/w=0/d=0, drop=r=0/w=0/d=0
latency : target=0, window=0, percentile=100.00%, depth=64
...
Disk stats (read/write):
dm-0: ios=6282561/2095989, merge=7155/926, ticks=7894293/4384448, in_queue=636612, util=99.60%, aggrios=3141864/1048246, aggrmerge=0/0, aggrticks=1780546/1331608, aggrin_queue=74596, aggrutil=99.92%
sdb: ios=0/0, merge=0/0, ticks=0/0, in_queue=0, util=0.00%
sda: ios=6283729/2096493, merge=0/0, ticks=3561093/2663217, in_queue=149192, util=99.92
This benchmark used a Pod in the same AZ as the preferred/active FSxN node. You can see that the read throughput for this test was around 126.7 MB/s at 31,682 IOPS and the write throughput was 42.2 MB/s at 10,562 IOPS. That is way faster than a standard gp2/gp3 volume for a 100 MB pod.
You can also see the ISCSI multipath effects. All operations went through dm-0, which distributes all of the IO to sda (the active FSxN node) and none to sdb (the passive FSxN node). We would see some split IO numbers if we had a failover during this benchmark.
As these benchmarks run relatively quickly and there is no instant way to provoke a failover on this managed service, I cannot show this case easily.
An interesting find during my experimentation is that the “Optimizing” state after resizing an FSxN filesystem to different throughput/IOPS will not impact the reported bandwidth or IOPS noticably. Good to know!
Next, for the latency: IOPing is a tool that measures the latency of write operations - it will write and read 4KB blocks by default and then report the minimum/average, and maximum latencies encountered. For access inside the same AZ, we end up around 0.6ms only.
> ioping -c 100 .
...
--- . (ext4 /dev/dm-0) ioping statistics ---
99 requests completed in 60.9 ms, 396 KiB read, 1.63 k iops, 6.35 MiB/s
generated 100 requests in 1.65 min, 400 KiB, 1 iops, 4.04 KiB/s
min/avg/max/mdev = 554.9 us / 614.9 us / 859.9 us / 38.0 us
Below you can see a table of the benchmarking I did and the corresponding benchmarks from an APN Container blog about the NAS variant
| Type | Avg IOPS Read | Avg IOPS Write | Avg Through Read | Avg Through Write | Avg Latency |
|---|---|---|---|---|---|
| NAS, same AZ | 37.5k | 12.5k | 154 MB/s | 51.3 MB/s | 484 µs |
| NAS, diff AZ | 33.4k | 11.1k | 137 MB/s | 45.6 MB/s | 1030 µs |
| SAN, same AZ | 31.7k | 10.6k | 127 MB/s | 42.2 MB/s | 615 µs |
| SAN, diff AZ | 24.1k | 8.0k | 96.3 MB/s | 32.1 MB/s | 858 µs |
Summary
This post showed how the combination of FSxN and EKS works using NetApp Trident. We have a working multi-AZ solution for applications that need block storage (not only EKS), and throughput and latencies are more than sufficient for most of your production workloads.
While I drafted a working solution for you to try out, please reach out to a consulting partner (ideally tecRacer) if you intend on creating a production workload with this combination. There are many things from a performance and security point in this post that would not be suitable for production works. Additionally, our consulting offer includes additional monitoring/compliance systems, the possibility to use third-party tooling with FSxN, and best practice documents to manage your filesystems.
I hope you enjoyed this post and would be happy if you reached out with questions and suggestions.
-
Sadly, Trident support for E-Series got discontinued by version 21.07 ↩︎